
This is one of the most asked DataStage scenario based interview questions. I will solve this problem by taking some sample data.
Input file:
Sno,name,salary,rank 1,Naveen,10000,2 2,Joe,20000,2 3,David,30000,1 4,Richard,30000,2 5,Obs,30000,1 1,Naveen,10000,2 1,Naveen,10000,2 3,David,30000,1 [\shell]
Output file:
2,Joe,20000,2 4,Richard,30000,2 5,Obs,30000,1 [\shell]
Final job design would be:

First sequential file stage used to read input file and you can see the duplicate and unique records here:

Populating one column ‘number’ in transformer stage. It has only value integer ‘1’ for all the records.

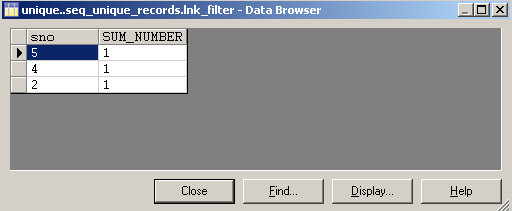
Summing the ‘number’ column by GROUPing ‘sno’ column. Here sno is the key column and we would get only sno column in the output. If we want to get other columns in output just place them in GROUP BY part(if requirement allows) or use the join stage to get the required columns.

Finally filtering the sum value in filter stage:

Run the job:

Final output would be:
You can watch the video tutorial of this post here:



 in DataStage – Job Design – 2){kind=link}